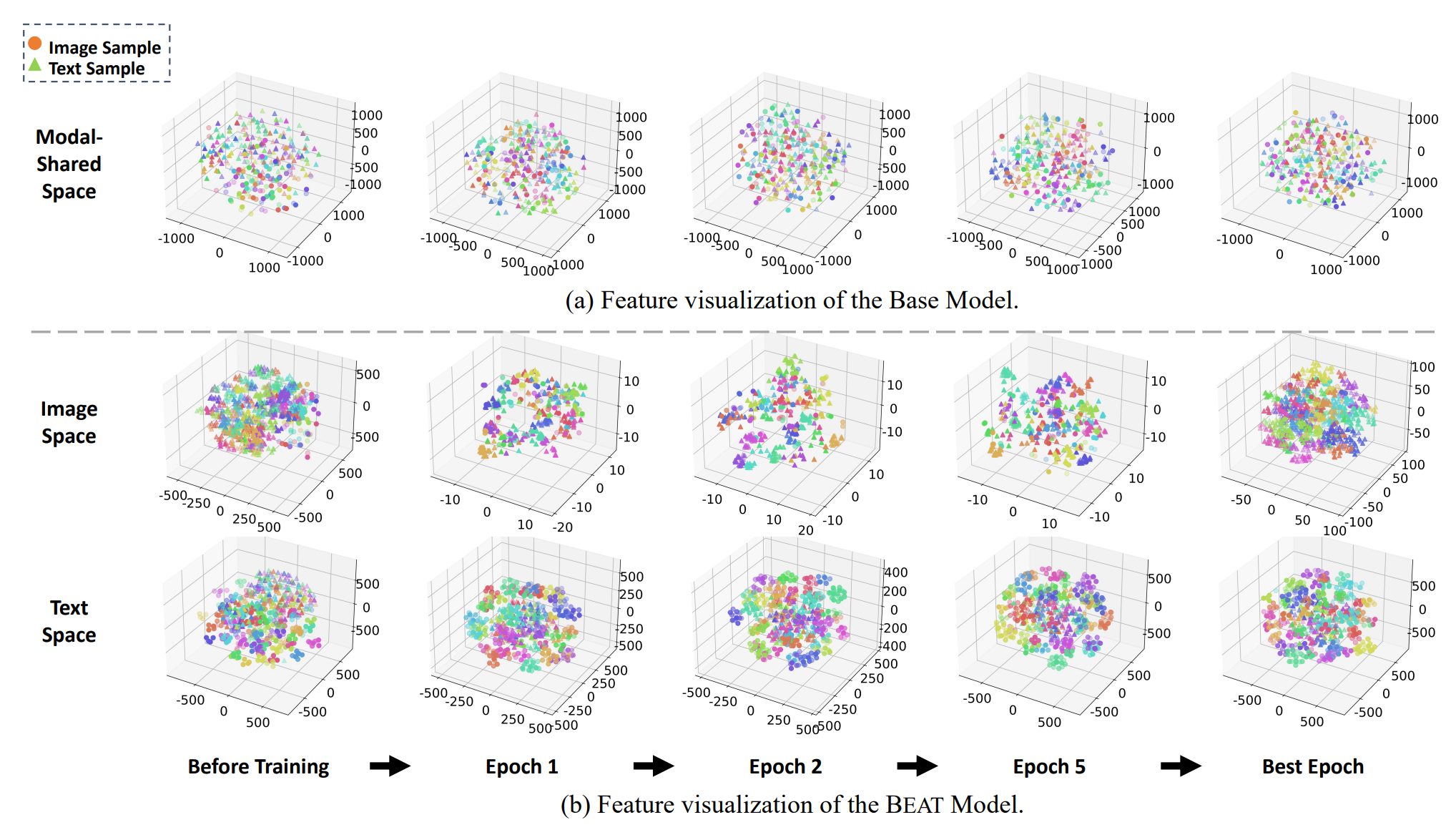
Model Architecture

Illustration of the proposed Beat model. Images and texts are first processed by ConvNet and SeqModel to obtain visual features 𝑽 and textual features 𝑻, respectively. Global features 𝒗𝑔 and 𝒕𝑔 are extracted through a global max pooling (GMP) and a fully connected layer (FC) based on 𝑽 and 𝑻. Similarly, we adopt a global max pooling (GMP) and an FC layer to obtain 𝐾 local visual features . Then, we employ word attention module (WAM) , GMP and FC layer to obtain 𝐾 local textual features . We then adopt a non-local module (NLM) to get 𝐾 non-local visual features and textual features . Afterward, the REM-G is introduced to perform bi-directional one-to-many embedding. Finally, textual and visual samples are aligned in two modal-specific spaces under the guidance of ID loss and CR loss.